
Trio: भौतिक संचालन के लिए एक विश्व मॉडल
Trio पर MachineFi Labs से एक स्थिति अपडेट — हमने क्या बनाया है, अभी क्या चल रहा है, और अपने कैमरों को इस पर कैसे लाएँ।




पूरे इतिहास में, भौतिक दुनिया को लोगों ने चलाया है। एक व्यक्ति देखता है कि क्या हो रहा है, आँकता है कि इसका क्या अर्थ है, और उस पर कार्य करता है — ट्रक चलाता है, लाइन पर काम करता है, फ़्लोर पर घूमता है। अनुभव करो, पूर्वानुमान लगाओ, कार्य करो: इस लूप में हमेशा एक इंसान की ज़रूरत रही है।
AI ने पहले डिजिटल दुनिया को बदला — भाषा, कोड, चित्र। अब यह भौतिक दुनिया पर शुरू हो रहा है। एक AI जो जीवंत ट्रैफ़िक में कार चलाता है। एक AI जो यह कल्पना करके वीडियो गेम सीखता है कि वह कैसे खेला जाता है। एक रोबोट जो कपड़ों का ढेर तह करता है। इन सबके नीचे जो हिस्सा है — वह चीज़ जो किसी मशीन को किसी स्थिति को देखने, यह कल्पना करने कि आगे क्या होगा, और उस पर कार्य करने देती है — वह एक विश्व मॉडल है। Trio एक अलग प्रकार का विश्व मॉडल है।
वे जान-बूझकर संकीर्ण हैं: एक कार, एक खेल, एक रोबोट, एक कार्य। लेकिन सबसे बड़ी भौतिक सतह पहले से ही जुड़ी हुई और देख रही है — हर गोदाम, स्टोर, कारखाने और देखभाल फ़्लोर के ऊपर लगे कैमरे, हज़ारों घंटे रिकॉर्ड करते हुए, जो आज लगभग कुछ नहीं बनाते सिवाय उस फुटेज के जिसे कुछ गलत होने के बाद खींचा जाता है। एक विश्व मॉडल जो उन पर चले — पूरे संचालनों पर, जीवंत — वही अवसर है। Trio इसी के लिए बना है।
Trio क्या है
ध्यान दें कि उन चारों में क्या समान है: हर एक एक चीज़ चलाता है — एक कार, एक खेल, एक रोबोट। कोई भी एक संचालन नहीं चलाता। और भौतिक अर्थव्यवस्था का अधिकांश हिस्सा वहीं रहता है — लंच रश में एक रेस्तराँ, एक कार वॉश जो कारों को अपने बे से होकर चक्र में ले जाता है, ट्रक लोड करता एक गोदाम, अपने फ़्लोर पर काम करता एक स्टोर, एक कारखाना लाइन — ऐसी जगहें जहाँ दर्जनों लोग, वाहन और मशीनें एक साथ चलते हैं, चौबीसों घंटे, और यह सब उन कैमरों पर जिन्हें देखने का समय किसी के पास नहीं है।
यही Trio के लिए है। Trio हमारा भौतिक संचालन के लिए विश्व-मॉडल प्लेटफ़ॉर्म है — कोई एकल अखंड मॉडल नहीं, बल्कि तीन उत्पादों का एक सुइट जो मिलकर एक जीवंत संचालन को अनुभव करते, पूर्वानुमान लगाते और उस पर कार्य करते हैं। जहाँ एक भाषा मॉडल सीखता है कि टेक्स्ट कैसे काम करता है, वहीं Trio सीखता है कि एक स्थान कैसे काम करता है — उसमें क्या है, वह कैसे चलता है, आगे क्या होता है — आपके संचालन के लिए, उन कैमरों से जो आपके पास पहले से हैं। हम भाषा मॉडल को प्रतिस्थापित नहीं करते; हम उन्हें भौतिक दुनिया देते हैं।
Trio उस लूप को तीन चरणों में चलाता है — और उसी क्रम में आता है। अनुभव आज जीवंत है; पूर्वदृष्टि और कार्य आगे आने वाले हैं।
आज, उनमें से दो वास्तविक हैं और आपके हाथों में हैं। Trio-Retina (देखना) किसी भी कैमरा फ़ीड को इस बात के एक मानक, जीवंत पाठ में बदल देता है कि क्या हो रहा है — कौन कहाँ है, क्या कर रहा है, कहाँ जा रहा है। Trio-Lumen (समझना) इसे सादी भाषा में प्रोग्राम-योग्य बनाता है — “समय-पश्चात लोडिंग डॉक में किसी को भी फ़्लैग करो” — चौबीसों घंटे हर फ़्रेम को देखते हुए और उसे घटनाओं और अलर्ट में बदलते हुए। अनुभव और समझ, आज आ रहे हैं।
pip install trio-retina
Trio-Retina ओपन सोर्स है — आपकी अपनी मशीन पर चलता है, या Playground में इसे जीवंत आज़माएँ →
वे दोनों वह नींव हैं जिस पर बाकी सब बना है। पूर्वदृष्टि और कार्य — मुसीबत के होने से पहले उसका अनुमान लगाना, फिर फ़्लोर पर कार्य करना — लूप के अगले चरण हैं। यह क्रम जान-बूझकर है: आप वह पूर्वानुमान नहीं लगा सकते जिसे आप अभी देख नहीं सकते, इसलिए हमने पहले दृष्टि बनाई।
खुले इंटरनेट पर प्रशिक्षित एक मॉडल सीखता है कि दुनिया कैसी दिखती है। Trio सीखता है कि आपका संचालन कैसे चलता है।
यह एक गोदाम में कैसा दिखता है
अमूर्तता हटा दें। एक लोडिंग डॉक, शिफ़्ट के बीच। एक फ़ोर्कलिफ़्ट एक बे से पीछे की ओर निकलती है; एक कर्मचारी दो रैक के बीच से एक ऐसे रास्ते पर बाहर आता है जो उसे काटता है। अभी तक कोई दूसरे को नहीं देख सकता।

देखना — Trio-Retina, कैमरे के पास एक छोटे बॉक्स पर चलते हुए, दोनों को पहले से ही ट्रैक की गई वस्तुओं के रूप में रखता है: फ़ोर्कलिफ़्ट और व्यक्ति, उनकी स्थितियाँ, और प्रत्येक किधर जा रहा है।
पूर्वानुमान — Trio का विश्व मॉडल अगले दो सेकंड आगे बढ़ाता है। दोनों रास्ते प्रतिच्छेद करते हैं। उसने ठीक यही ज्यामिति पहले बुरी तरह समाप्त होते देखी है।
कार्य — एक नियतात्मक एज सुरक्षा गेट लगभग 50 मिलीसेकंड में प्रतिच्छेदन अलार्म दागता है — इससे तेज़ कि कोई भी व्यक्ति प्रतिक्रिया कर सके — और फ़ोर्कलिफ़्ट को रुकने का संकेत दिया जाता है। एक दुर्घटना रिपोर्ट के बजाय एक बाल-बाल बचना।
यही पूरा सिद्धांत एक ही फ़्रेम में है: वह फुटेज नहीं जिसे कुछ होने के बाद आप खींचते हैं, बल्कि एक निर्णय जो उसके होने से ठीक पहले उस क्षण लिया गया।
एक वास्तविक विश्व मॉडल — और हमारा कैसे अलग है
Trio एक तेज़ी से आगे बढ़ते क्षेत्र के भीतर बैठता है। विश्व मॉडल वहाँ हैं जहाँ AI के बहुत से श्रेष्ठ दिमाग अब इशारा कर रहे हैं। यह विचार Ha व Schmidhuber के World Models (2018) तक जाता है — एक एजेंट जो अपने वातावरण का एक संक्षिप्त मॉडल सीखता है और उसके भीतर रोलआउट का “सपना” देखता है। Yann LeCun तर्क देते हैं कि अव्यक्त (latent) स्थान में एक पूर्वानुमानी विश्व मॉडल (उनका JEPA) स्वायत्त मशीन बुद्धिमत्ता के मार्ग पर छूटा हुआ टुकड़ा है; Fei-Fei Li इस सीमांत को स्थानिक बुद्धिमत्ता कहती हैं, और उनकी World Labs ऐसे मॉडल बनाती है जो अन्वेषण-योग्य 3D दुनियाएँ उत्पन्न करते हैं। यह क्षेत्र मोटे तौर पर खेमों में बँटता है:
- अव्यक्त पूर्वानुमान — V-JEPA 2 (Meta) और Dreamer शृंखला अव्यक्त स्थान में गतिकी सीखते हैं और उसके भीतर योजना बनाते हैं।
- जनरेटिव व इंटरैक्टिव दुनियाएँ — Genie 3 (DeepMind), NVIDIA Cosmos, और World Labs का Marble वातावरणों की कल्पना और उत्पादन करते हैं।
- ड्राइविंग — Tesla FSD और Wayve का GAIA-2 पृथ्वी पर सबसे अधिक तैनात विश्व मॉडल चलाते हैं — एक कार के लिए।
- रोबोटिक्स — Physical Intelligence, Skild AI, और Figure एक ही रोबोट के लिए आधारभूत मॉडल बनाते हैं।
उनमें से लगभग सभी या तो एक दुनिया की कल्पना या अनुकरण करते हैं, या एक एकल एजेंट के अहं-केंद्रित डोमेन का मॉडल बनाते हैं — एक कार, एक रोबोट। Trio वह है जो जीवंत, वास्तविक, पहले से मौजूद तृतीय-पुरुष संचालनों पर चलता है — एक पूरा गोदाम या स्टोर, एक साथ कई लोग और मशीनें — और उन पर वास्तविक समय में कार्य करता है।
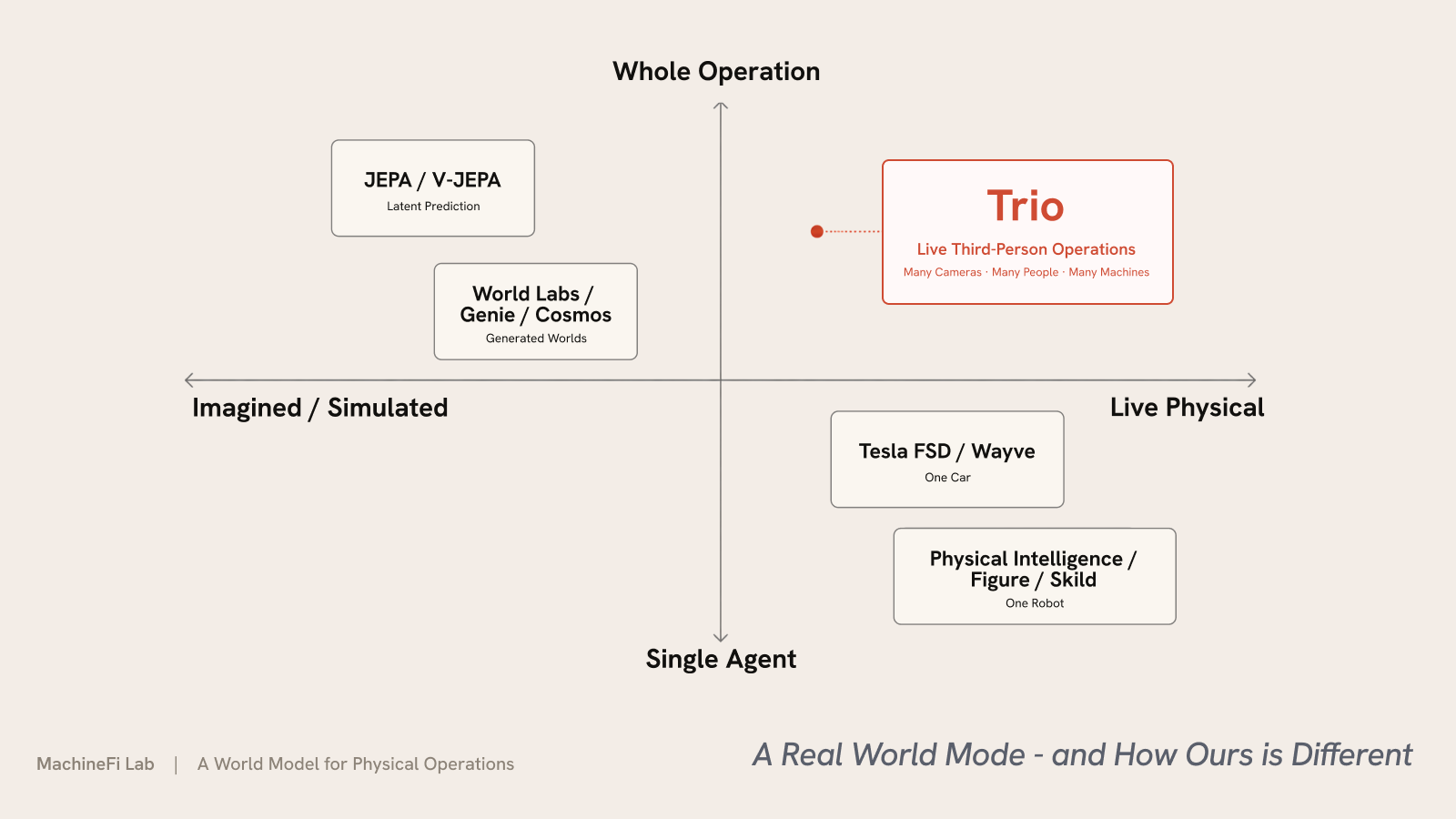
| विश्व मॉडल | किसके लिए अनुकूलित | Trio कैसे भिन्न है |
|---|---|---|
| JEPA · V-JEPA (LeCun) | अव्यक्त स्थान में सामान्य विश्व मॉडल सीखना — शोध | जीवंत संचालनों पर एक तैनात उत्पाद; विशेषीकृत, कोई वास्तुकला नहीं |
| World Labs (Fei-Fei Li) | अन्वेषण-योग्य 3D दुनियाओं का उत्पादन व पुनर्निर्माण | उस दुनिया को पढ़ता है जिसे आपके कैमरे पहले से देखते हैं; कोई उत्पन्न नहीं करता |
| Genie · Cosmos | वातावरणों की कल्पना व अनुकरण | पहले से मौजूद स्थानों पर वास्तविक समय में निर्णय लेता है |
| Tesla FSD | एक कार चलाना — अहं-केंद्रित, एकल डोमेन | तृतीय-पुरुष, बहु-इकाई, एक पूरा संचालन, कई डोमेन |
| Physical Intelligence · Figure · Skild | एक रोबोट, एक कार्य | तर्क करता है कि एक पूरे संचालन को आगे क्या करना चाहिए |
दो अक्ष Trio को अलग करते हैं। तकनीकी रूप से — यह छोटा, तेज़ और विशेषीकृत है: एज पर वास्तविक समय में, लगभग $0.004 प्रति क्वेरी का तल, प्रति निर्णय बिल किया गया, एक जमे हुए आधार के साथ छोटे प्रति-साइट एडाप्टर (LoRA, GPU-घंटों में प्रशिक्षित) के बजाय हर फ़्रेम पर फिर से चलाया जाने वाला एक विशाल सामान्य मॉडल। OVBench स्ट्रीमिंग बेंचमार्क पर, एक ओपन-वेट मॉडल को Trio के स्टैक में लपेटना केवल वास्तुकला से सटीकता को +2.3 अंक बढ़ाता है, और इसका अनुभव बिना उन निश्चित मिनट-सीमाओं के स्ट्रीम करता है जिन पर अग्रणी मॉडल रुक जाते हैं। परिदृश्य के अनुसार — यह उन संचालनों पर चलता है जो पहले से मौजूद हैं, और उन पर अभी कार्य करता है, बजाय एक दुनिया की कल्पना करने, एक कार चलाने, या एक रोबोट को हिलाने के।
Trio कैसे बना है
तकनीकी टीमों के लिए: यहाँ बताया गया है कि Trio हर कैमरे पर पूरे दिन चलने के लिए पर्याप्त तेज़ और सस्ता कैसे रहता है। यदि आप संचालन की कहानी के लिए यहाँ हैं, तो आगे स्किम करें — निष्कर्ष अंतिम पंक्ति है।
पाँच सिद्धांत इस सिस्टम को एक साथ बाँधते हैं: परतों के बीच हर इंटरफ़ेस एक दृढ़-प्रकार वाला, निरीक्षण-योग्य दृश्य ग्राफ़ है (कभी कोई अपारदर्शी वेक्टर नहीं); एक राउटर लागत का स्वामी है, सस्ती परतों को निरंतर चलाता है और महँगे तर्क को केवल आवश्यकता पड़ने पर जगाता है; उपकरण द्वि-दिशात्मक हैं, इसलिए तर्क परत निचली परतों को पुनः जाँचने या पुनः अनुकरण करने का आदेश दे सकती है; हर निर्णय अपने साक्ष्य के साथ आता है, इसलिए एक ऑपरेटर उसका निरीक्षण, विवाद और अधिक्रमण कर सकता है; और आधार मॉडल जमे रहते हैं जबकि छोटे प्रति-परिनियोजन एडाप्टर — LoRA मॉड्यूल और एक क्रॉस-टियर फ़्यूज़न एडाप्टर, पूर्ण पुनर्प्रशिक्षण के बजाय GPU-घंटों में प्रशिक्षित — प्रत्येक साइट को विशेषीकृत करते हैं।
ये सिद्धांत सात तलों के रूप में साकार होते हैं — एक एकल निर्णय के मार्ग में छह, साथ ही सभी पर अभिशासन:
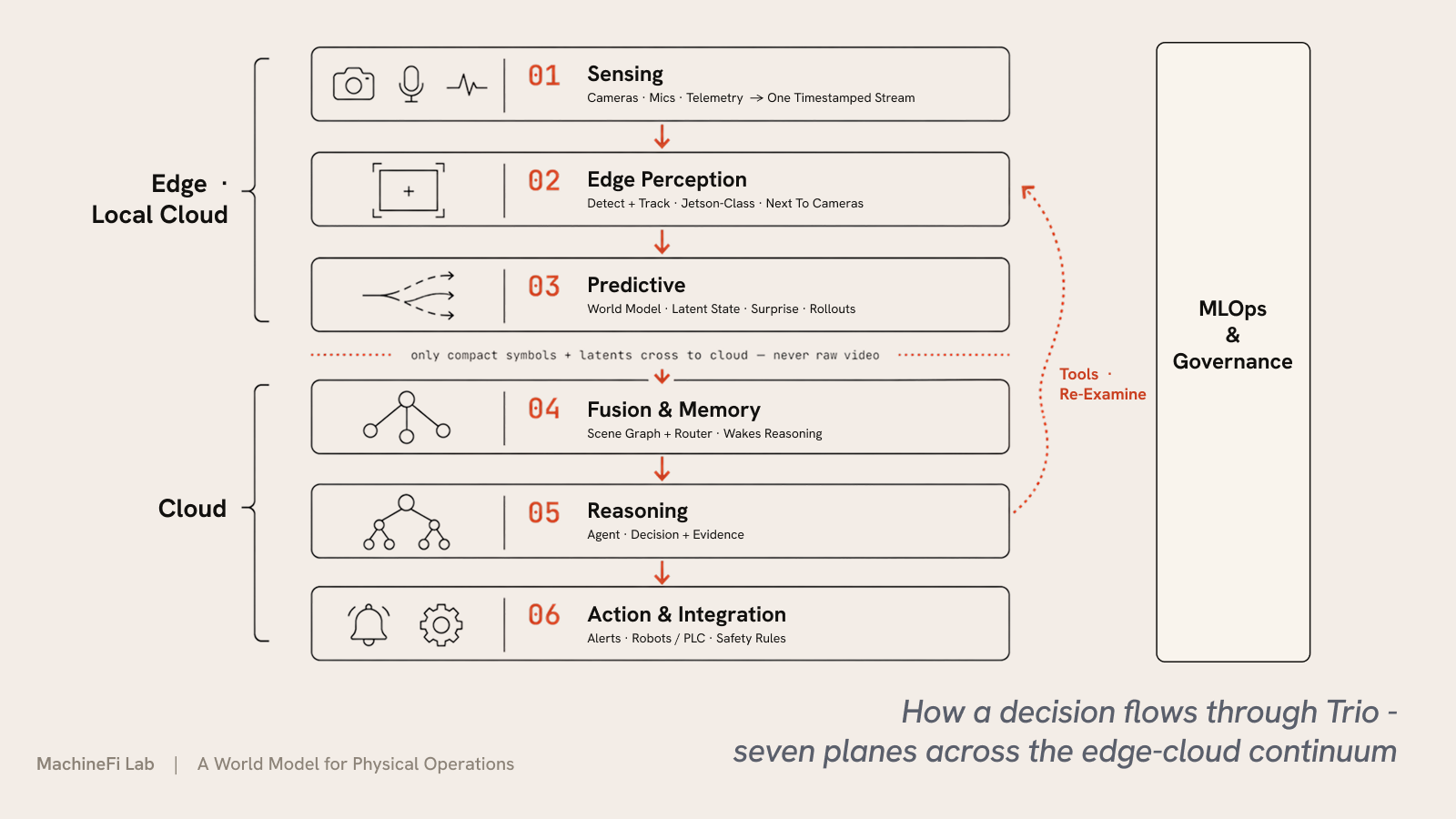
चूँकि अनुभव और पूर्वानुमान स्थानीय रूप से चलते हैं और केवल संक्षिप्त प्रतीक व अव्यक्त मान क्लाउड तक जाते हैं — कभी कच्चा वीडियो नहीं — Trio प्रति निर्णय बिल किया जाता है, प्रति फ़्रेम प्रति टोकन नहीं।
Trio कहाँ चलता है
गोदाम एक फ़्रेम था। जिस रेस्तराँ, कार वॉश, स्टोर, कारखाने से हमने शुरुआत की — वही मॉडल किसी भी ऐसे संचालन की ओर इशारा करता है जो कैमरों पर चलता है, आज मानव ऑपरेटरों के साथ-साथ, उसे सामने लाते हुए जो उनके मौजूदा सिस्टम चूक जाते हैं:








हमने क्या बनाया है — और आगे क्या है
Trio अब व्हाइटबोर्ड पर एक थीसिस नहीं है। v1.0 तकनीकी रिपोर्ट पूरे सिस्टम को औपचारिक रूप देती है — अनुभव–पूर्वानुमान–कार्य स्टैक, पाँच सिद्धांत, सात तल — दो पूरी तरह से काम किए गए संदर्भ डोमेन (एक कार वॉश और एक गोदाम) के साथ, ऊपर बताए गए फ़ोर्कलिफ़्ट-और-पैदल यात्री वाले बाल-बाल बचने तक, जिसे एक नियतात्मक एज सुरक्षा गेट ने पकड़ा जो लगभग 50 मिलीसेकंड में दागता है, 100 मि.से. की सीमा के भीतर अच्छी तरह। Trio-Retina ओपन सोर्स है (pip install trio-retina), और Playground जीवंत है — platform.machinefi.com/playground खोलें और अपने ब्राउज़र में Trio को असली फुटेज पढ़ते देखें।
तीन शक्तियाँ अभी को वह क्षण बनाती हैं: एज सिलिकॉन अंततः क्लाउड राउंड-ट्रिप के बिना वास्तविक समय का परिचालन तर्क चला सकता है; बहु-इकाई दृश्य समझ एक शोध सीमा पार कर चुकी है जिसके पास एकल-वस्तु पहचान कभी नहीं पहुँची; और भौतिक वातावरणों के ऑपरेटर शायद आज के AI में सबसे कम-मूल्यांकित क्षमता के लिए तैयार हैं — उन कैमरों के ऊपर एक विश्व मॉडल जो उनके पास पहले से हैं, बिना नए हार्डवेयर के। यहाँ से, Trio लूप में ऊपर बढ़ता है — आज देखने और समझने से पूर्वानुमान की ओर और, समय आने पर, फ़्लोर पर कार्य करने की ओर।
आज ही Trio से शुरुआत करें
दो रास्ते — दोनों अभी जीवंत हैं:
GitHub पर Trio-Retina
ओपन-सोर्स अनुभव परत — मॉडल-अज्ञेय स्थिति परत जो किसी भी डिटेक्टर को घटनाओं की एक मानक स्ट्रीम प्लस अव्यक्त स्थिति में बदल देती है। pip install trio-retina और इसे अपनी मशीन पर चलाएँ।
प्लेटफ़ॉर्म पर Trio-Lumen
अपने संचालन को ब्राउज़र में जीवंत होते देखें — Trio असली फुटेज को स्थिति वाली वस्तुओं और भीड़ को प्रवाह के रूप में पढ़ता है, फिर इसे अपने कैमरों की ओर मोड़ें और सादी भाषा में पूछें।
Trio-Lumen को जीवंत आज़माएँ →— MachineFi Labs टीम
विश्व मॉडल पर आगे पढ़ें
- D. Ha, J. Schmidhuber. World Models. 2018.
- Y. LeCun. A Path Towards Autonomous Machine Intelligence. 2022. (JEPA प्रस्तुत करता है)
- F.-F. Li. From Words to Worlds: Spatial Intelligence is AI’s Next Frontier. 2025. (World Labs)
- D. Hafner, W. Yan, T. Lillicrap. Training Agents Inside of Scalable World Models (DreamerV4). 2025.
- Meta AI. V-JEPA 2. 2025.
- DeepMind. Genie 3. 2025.
- NVIDIA. Cosmos World Foundation Model Platform for Physical AI. 2025.
- Wayve. GAIA-2: a controllable multi-camera world model for driving. 2025.